Pourquoi l'intelligence artificielle pour les institutions financières ?
L'intelligence artificielle (IA) est un domaine qui combine l'informatique et l'analyse de données pour résoudre des problèmes de la vie réelle. L'intelligence artificielle est peut-être née dans des œuvres de fiction, mais elle a commencé à montrer sa véritable puissance lorsqu'AlphaGo, un modèle d'IA qui joue au jeu de société Go, est devenu imbattable en 2016. C'était étonnant, car on pensait que le jeu de Go était trop compliqué pour les ordinateurs, du moins pour quelques décennies encore. Mais aussi impressionnant que soit AlphaGo, il s'agit toujours d'une IA faible. Aujourd'hui, les développeurs d'IA travaillent à l'élaboration d'une IA forte. ChatGPT et GPT-4 sont certainement les percées les plus récentes qui nous montrent que l'IA n'est pas seulement quelque chose de futur - elle est là maintenant.
L'IA est déjà appliquée dans de nombreux secteurs et domaines de recherche où de nombreuses données sont disponibles. Les services financiers sont certainement l'un de ces secteurs. Par exemple, l'assistant financier IA de Bank of America, Erica, est l'un des modèles les plus avancés et l'un des premiers modèles largement disponibles. Depuis son lancement en 2018, Erica a aidé près de 32 millions de clients de Bank of America à gérer leur vie financière. Il apprend au fil des conversations avec les clients et étend ses capacités en permanence. Il existe de nombreuses autres applications de l'IA dans le secteur des services financiers, notamment l'acquisition et l'accueil des clients, la connaissance du client (KYC), la prise de décision en matière de crédit, la segmentation, la fidélisation et la vente croisée, pour n'en citer que quelques-unes.
Dans ce document, nous aborderons quelques termes et algorithmes clés de l'IA, suivis de quelques cas d'utilisation de l'IA dans le secteur des services financiers et d'une analyse des tendances.
Qu'est-ce que la science des données et l'intelligence artificielle ? ?
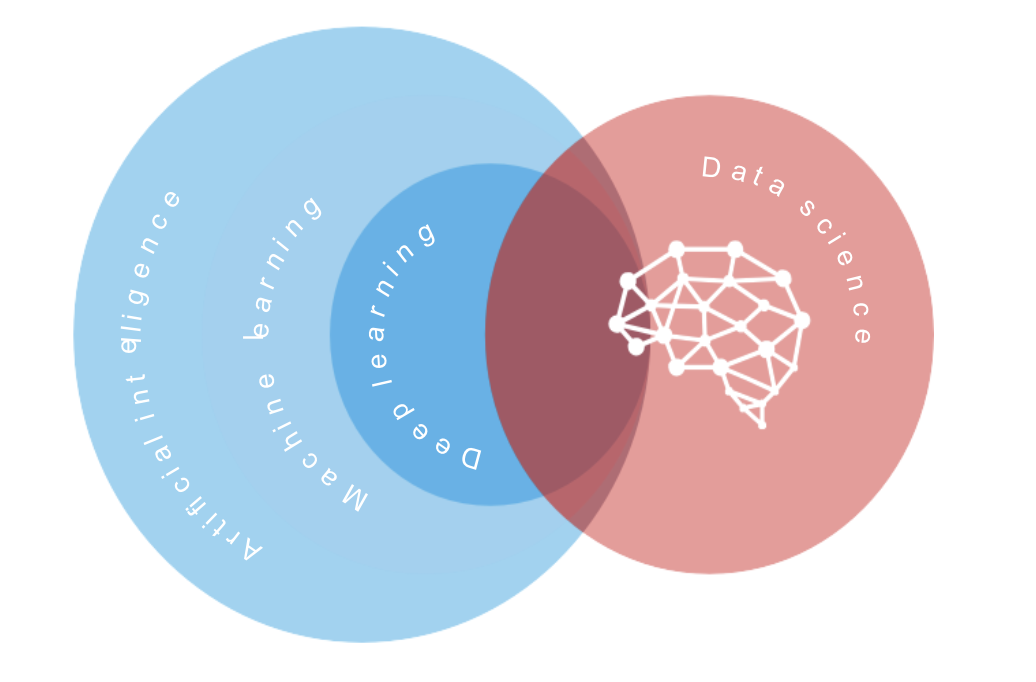
La science des données (SD) est un domaine d'étude interdisciplinaire qui utilise divers modèles statistiques et informatiques pour extraire des informations et des connaissances précieuses à partir de données bruyantes. L'intelligence artificielle (IA) désigne le domaine d'étude qui simule l'intelligence humaine pour mener à bien les processus d'apprentissage, de réflexion et d'action.
L'apprentissage automatique est une branche de l'intelligence artificielle qui permet aux machines d'apprendre et de s'améliorer. Dans le domaine de l'apprentissage automatique, il existe un domaine subsidiaire spécialisé dans l'utilisation de réseaux neuronaux pour apprendre des modèles à partir de données. Il s'agit de l'apprentissage profond (deep learning, DL). Étant donné que l'apprentissage automatique, par construction, implique le développement d'un modèle et son entraînement à l'aide de données, il s'appuie fortement sur des méthodes mathématiques, statistiques et informatiques pour calibrer le modèle à l'aide de données brutes. Cela recoupe le domaine de la science des données.
Figure 1 Relations entre l'IA, l'apprentissage automatique (ML) et la science des données (DS)
Brève introduction au glossaire commun
- Traitement du langage naturel
Le traitement du langage naturel (NLP) permet aux machines de lire et de comprendre le langage humain sous la forme de données structurées et non structurées. Le traitement du langage naturel a été largement adopté dans le secteur des services financiers, de la banque de détail aux fonds spéculatifs. Parmi les techniques de traitement du langage naturel, citons l'extraction de données à partir de rapports ou de médias sociaux, l'analyse des sentiments, la réponse à des questions, etc. - Apprentissage automatique
L'apprentissage automatique est une branche de l'IA et de l'informatique qui se concentre sur l'utilisation de données et d'algorithmes pour imiter la façon dont les humains apprennent, en améliorant progressivement la précision. Il existe trois types d'apprentissage automatique.
Tableau 1 Classification de l'apprentissage automatique

- Big dataLes modèles d'IA et d'apprentissage automatique ont besoin d'une grande quantité de données d'entraînement pour améliorer les algorithmes d'apprentissage. L'étiquetage d'énormes quantités de données est un processus préalable à l'entraînement d'un modèle d'apprentissage automatique. Il s'agit souvent d'un processus à forte intensité de main-d'œuvre qui occupe généralement la majeure partie du temps d'un projet d'apprentissage automatique. Cependant, les big data ont une relation synergique avec l'IA et l'apprentissage automatique. En introduisant les big data dans les algorithmes d'apprentissage automatique, la précision et l'efficacité de la prise de décision sont grandement améliorées. L'IA et les big data travaillent ensemble pour offrir de meilleures solutions en matière de services à la clientèle, de gestion des risques, de génération d'informations, etc.Le terme "big data" désigne les ensembles de données massives et complexes qui sont difficiles à traiter à l'aide des méthodes traditionnelles de traitement des données. Les Big Data peuvent également être décrites à l'aide des "trois V" : volume, vitesse et variété. Le volume représente la taille et la quantité de données ; la vitesse représente la vitesse de génération et de transfert des données ; et la variété fait référence au type et à la nature des données. La variété peut être classée en trois catégories : les données structurées, les données semi-structurées et les données non structurées.
- Données structurées
Les données structurées ont été organisées dans un format prédéfini, suivant un ordre cohérent. Les données sont généralement stockées dans des bases de données relationnelles, telles que les bases de données SQL, ou dans des feuilles de calcul. Le format bien défini des données structurées facilite leur stockage et leur accès. - Données semi-structurées
Les données semi-structurées possèdent certaines propriétés organisationnelles, mais elles ne sont pas complètement structurées ni associées à des bases de données relationnelles (par exemple, le courrier électronique). Elles contiennent certains éléments structurels, notamment des balises ou d'autres indicateurs qui facilitent leur analyse. - Données non structurées
Les données non structurées ne sont pas organisées dans un format prédéfini, comme les données audio ou les images. On estime que plus de 80% des données générées ou collectées par les organisations sont non structurées. Ce type de données représente un volume important, mais il est difficile à analyser. - Réseaux neuronaux artificiels (RNA)
Les réseaux neuronaux artificiels d'apprentissage profond utilisent plusieurs couches pour le calcul, notamment la couche d'entrée, les couches cachées et la couche de sortie. Les couches sont composées de nœuds (ou neurones) qui sont analogues aux neurones biologiques humains.Figure 2 Réseau neutre artificiel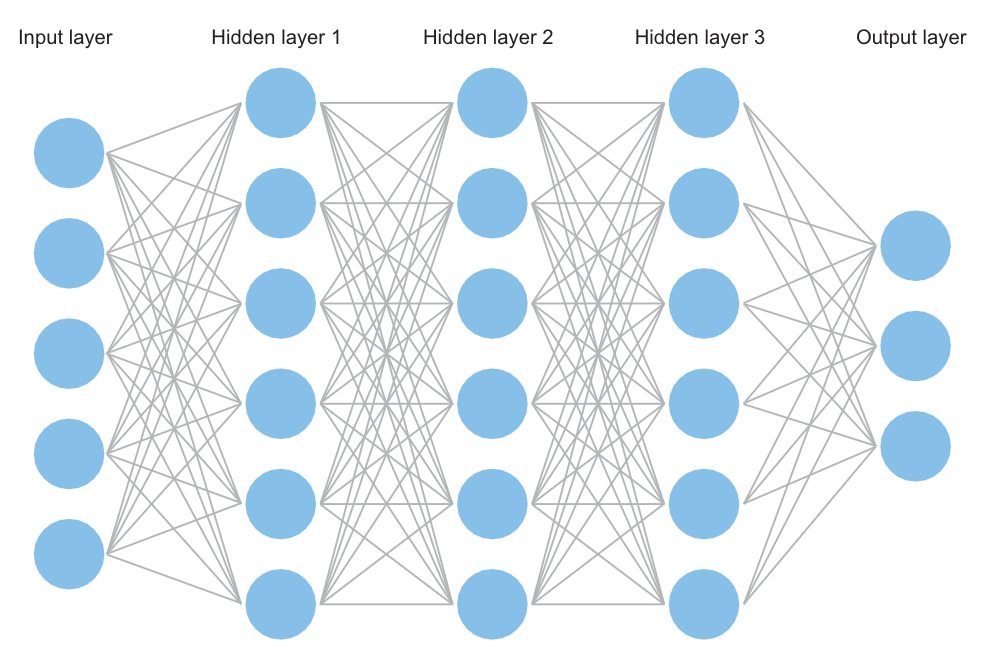
Lorsque le nombre de couches cachées est suffisant, la collection de couches cachées est profonde et on parle d'apprentissage profond. Les couches cachées extraient les données de la couche d'entrée, calculent et déterminent si la valeur de l'information est suffisante pour être transmise aux neurones suivants, conformément à la règle d'apprentissage. Si c'est le cas, le neurone est activé et l'information est transmise à la couche suivante et une sortie est générée après un processus itératif. Les différences entre les sorties modélisées et les sorties ciblées sont utilisées pour ajuster les associations pondérées des réseaux par rétropropagation.
Principales applications dans le secteur bancaire
- 1a. Détection de la fraudeDepuis des années, la fraude est un problème crucial dans le secteur bancaire. Alors que les clients effectuent de plus en plus de transactions numériques et en ligne via une plus grande variété d'options de paiement, telles que les cartes de crédit ou les portefeuilles numériques, les risques d'activités frauduleuses sont plus élevés. Un modèle efficace de gestion du risque de fraude est très important pour les banques car il leur permet d'atténuer les pertes dues à la fraude. Les banques peuvent utiliser des modèles basés sur l'apprentissage automatique pour reconnaître les schémas cachés dans les transactions frauduleuses. Dans une approche traditionnelle ou basée sur des règles, des règles doivent être établies pour identifier les transactions suspectes. Cependant, les fraudeurs sont de plus en plus avertis sur le plan technologique. Ils sont capables d'utiliser les derniers développements technologiques et des schémas plus sophistiqués pour frauder les banques. Par conséquent, les banques ne peuvent pas prédire la fraude avec précision à l'aide de règles strictes. Il est nécessaire d'analyser le modèle de données qui pourrait se développer et répondre instantanément à de nouvelles situations. Un algorithme d'apprentissage non supervisé a été utilisé pour la détection des fraudes, car le modèle est capable d'analyser les données et d'évoluer sans supervision humaine. Il peut ainsi identifier les similitudes cachées entre les transactions frauduleuses. En outre, les réseaux neuronaux sont également utilisés pour la modélisation de la détection des fraudes, car ils peuvent modéliser des interactions non linéaires et complexes basées sur l'informatique cognitive. C'est d'autant plus pratique que de nombreuses relations entre les entrées et les sorties des transactions frauduleuses sont non linéaires et complexes.
- 1b. Étude de cas : Danske BankLa Danske Bank est la plus grande banque du Danemark et joue un rôle important dans la région de l'Europe du Nord en servant plus de 5 millions de clients particuliers. Cependant, elle utilisait manuellement un modèle traditionnel de détection des fraudes, avec peu d'efficacité et de précision. La Danske Bank était confrontée à un faible taux de détection des fraudes de 40%, car le modèle identifiait chaque jour 1 200 cas de faux négatifs. Le nombre considérable de faux cas a alarmé la Danske Bank, ce qui l'a poussée à moderniser son modèle de détection des fraudes afin d'identifier les fraudes avec plus de précision.Dankse Bank a intégré un logiciel d'apprentissage en profondeur avec des unités de traitement graphique (GPU) optimisées pour l'apprentissage en profondeur. La solution améliorée par l'apprentissage profond a aidé la banque à identifier les cas de fraude potentiels et à réduire les faux positifs. La main-d'œuvre nécessaire pour prendre des décisions opérationnelles a également été réduite car le processus a été transféré au système d'IA. Les systèmes d'apprentissage profond de la banque comparent les modèles en temps réel en utilisant la méthodologie "champion/challenger" pour identifier les modèles les plus productifs. Différents modèles "challenger" analysent simultanément les données en temps réel et apprennent à partir du flux de données. La Danske Bank a ainsi pu réduire de 60% le nombre de faux positifs et augmenter de 50% le nombre de vrais positifs. Danske Bank peut désormais détecter plus efficacement les fraudes grâce au déploiement de technologies d'apprentissage profond.
- 2a. Évaluation du risque de créditLe risque de crédit est généralement le risque financier le plus important pour les banques commerciales. Pour tous les types de prêts, les banques doivent déterminer le risque de défaillance de leurs clients. Dans le passé, les banques géraient efficacement le risque de crédit à l'aide de modèles statistiques prédictifs. Par exemple, les modèles de régression logistique sont parmi les plus utilisés pour estimer la probabilité de défaut. Cependant, à l'ère du big data, les banques peuvent utiliser des algorithmes d'IA pour analyser beaucoup plus de données, en particulier celles qui ne sont pas structurées par nature, par exemple les données des médias sociaux ou les données de litiges provenant de sites web judiciaires. L'utilisation efficace de ces données permet d'améliorer le pouvoir prédictif des modèles et donc d'aider les banques à prendre de meilleures décisions de crédit et à optimiser la performance du portefeuille.Les informations traditionnelles telles que les ratios financiers, les profils d'entreprise et les données démographiques des emprunteurs sont couramment utilisées pour le développement de modèles d'évaluation du crédit. Cependant, comme les données de certaines PME peuvent ne pas être suffisantes pour construire une carte de score valide, l'adoption de données alternatives, y compris les données de télécommunication, les dossiers d'expédition et les traits comportementaux, est essentielle. Les modèles d'apprentissage automatique permettent l'utilisation la plus efficace de ces données alternatives, car elles peuvent se présenter sous des formes non structurées ou semi-structurées.
- 2b. Étude de cas : une grande banque en ligne chinoise (affiliée à Alibaba)MYBank est une banque en ligne chinoise de premier plan. Elle propose des prêts en ligne aux petites et moyennes entreprises (PME). Depuis sa création en 2015, la banque a accordé des prêts à plus de 45 millions de PME. En juillet 2022, la MYbank du groupe Ant a lancé le système de gestion du risque intelligent "Bailing" afin d'appliquer la technologie de l'IA à l'approbation des prêts. Le système Bailing permet aux clients, en particulier aux propriétaires de petites et microentreprises, de prouver leur solidité et leur stabilité opérationnelles en prenant simplement des photos de leurs justificatifs. Les technologies NLP ont permis d'identifier automatiquement 26 types de justificatifs, allant des contrats aux factures en passant par les licences d'exploitation. Lors du test de contrôle, l'identificateur d'IA basé sur le NLP a démontré une cohérence 95% avec l'examen manuel, tout en améliorant considérablement l'efficacité de l'identification des justificatifs. Depuis sa création, plus de 5 millions de clients ont obtenu des prêts par l'intermédiaire du système Bailing sans interaction humaine.
- 3a. Segmentation de la clientèleLe secteur bancaire a été l'un des premiers à adopter l'idée de cibler des clients spécifiques à l'aide d'une analyse de segmentation. La segmentation de la clientèle permet aux banques de diviser leurs diverses bases de clients en groupes en fonction de différents critères, tels que les besoins des clients, la qualité du crédit et la rentabilité. Les banques peuvent ainsi atteindre différents objectifs. Une analyse de segmentation bien conçue permet aux banques de comprendre parfaitement leurs clients et d'améliorer l'expérience client grâce à des produits plus personnalisés.Afin de mieux comprendre les données des clients et de les segmenter en groupes, les banques modernes pourraient utiliser des modèles d'intelligence artificielle et d'apprentissage automatique. Les banques observent les modèles cachés ou les caractéristiques communes dans les données en utilisant efficacement les modèles d'apprentissage automatique. L'algorithme classera les clients en différents groupes. Par exemple, la banque peut utiliser des attributs communs tels que les données démographiques, les étapes de la vie, les niveaux de revenus, etc. Par la suite, la banque peut concevoir et sélectionner une campagne de marketing sur mesure ou des suggestions pour les clients.
- 3b. Regroupement par K-meansK-Means est un algorithme d'apprentissage non supervisé couramment adopté pour le regroupement (affectation de données d'entrée à des groupes à l'aide de modèles de données).Figure 3 Regroupement par K-means
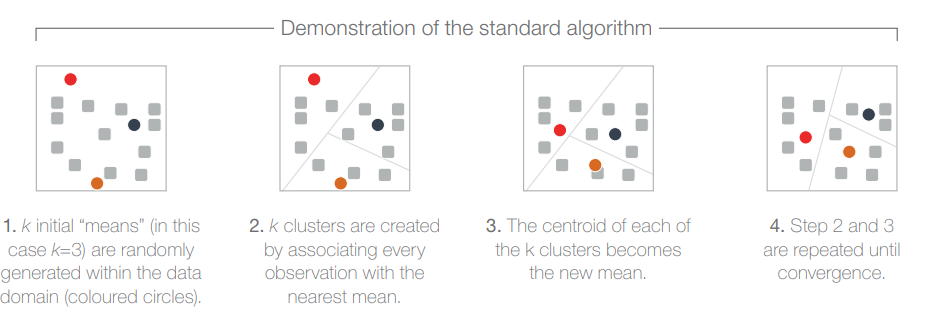
- 3c. Étude de cas : une grande banque du Moyen-OrientUne grande banque du Moyen-Orient a rencontré de nombreux problèmes ces dernières années en raison de la médiocrité de son service à la clientèle et de son orientation vers les consommateurs. Une étude a donc été menée pour répartir les clients de la banque en groupes en fonction des avantages escomptés. La banque a aidé les chercheurs dans leur recherche en fournissant les informations appropriées et en travaillant en étroite collaboration avec l'équipe de recherche.Dans le projet, l'analyse K-Means a été utilisée pour effectuer la segmentation et établir le nombre de segments. Certaines informations démographiques sur les clients (par exemple, le sexe, la situation de famille) ont été utilisées dans l'analyse de regroupement, ce qui a permis de séparer quatre segments distincts en fonction des avantages escomptés. Les quatre groupes de clients sont ceux qui sont axés sur les avantages, la paix, les intérêts et les clients modérés, car ces groupes ont démontré des attributs de données importants. En conséquence, la banque peut choisir le plan marketing idéal et créer un programme publicitaire approprié en fonction des caractéristiques des clients.
Applications clés dans la gestion des actifs
- 4a. Le robot-conseilLes robots-conseillers sont des conseillers financiers numériques qui fournissent des services d'investissement ou de planification financière pilotés par des algorithmes d'IA et de ML. Les robots-conseillers utilisent le traitement du langage naturel (NLP) pour comprendre les données en langage naturel (par exemple, la voix et le texte) et interagir avec les investisseurs sous la forme de chatbots, ce qui réduit la supervision humaine et abaisse ainsi la barrière d'entrée pour les investisseurs de détail. Par exemple, les robots-conseillers peuvent être utilisés pour recueillir des informations sur les investisseurs (par exemple, les objectifs de rendement et l'appétit pour le risque) par le biais de questionnaires comportementaux. Les robo-advisers peuvent également être utilisés pour répondre aux questions fréquemment posées.
- 4b. Gestion du portefeuilleLe NLP est devenu un outil efficace dans la gestion de portefeuille car il est capable d'extraire des informations de différents formats non structurés et semi-structurés, tels que les rapports annuels, les articles de presse et les messages sur les médias sociaux. Au lieu des approches traditionnelles basées sur des dictionnaires qui extraient des informations uniquement à partir de mots individuels, les approches d'IA peuvent également interpréter le contexte et les tonalités.Figure 4 Gestion de portefeuille
Certaines sociétés de gestion d'actifs utilisent des modèles d'apprentissage automatique pour réaliser des analyses fondamentales sophistiquées, y compris l'analyse de données semi-structurées provenant de l'actualité ou de rapports financiers. Les approches d'IA telles que les machines à vecteurs de support pourraient générer des informations sur de nombreux titres, identifier les corrélations entre différentes classes d'actifs et fournir des estimations plus précises sur les covariances et les rendements attendus.Dans l'optimisation de portefeuille, les approches traditionnelles se concentrent sur la couverture et l'analyse quantitative, tandis que les techniques d'apprentissage automatique peuvent traiter et extraire des informations à partir de quantités extrêmement importantes de données. En outre, l'apprentissage automatique peut facilement appliquer des techniques non linéaires et réduire la dimensionnalité, ce qui permet d'obtenir de meilleures performances hors échantillon. En outre, l'apprentissage par renforcement permet à la machine de s'améliorer continuellement et de traiter des problèmes complexes d'allocation d'actifs qu'aucun humain ne peut résoudre.4c. Étude de cas : UOB Asset Management (UOBAM)United Overseas Bank (UOB) est une banque de premier plan en Asie avec 500 bureaux dans le monde entier. Son nouveau produit, UOBAM Invest, est le premier robo-advisor de Singapour sur un portefeuille mobile et comprend des solutions d'investissement durable. Il compte des millions d'utilisateurs et le total des actifs sous gestion a dépassé les 36,5 milliards de dollars singapouriens.Le robo-advisor utilise des algorithmes de profil de risque et de définition d'objectifs pour s'assurer que les recommandations d'investissement proposées par l'algorithme sont alignées sur les niveaux de tolérance au risque et les objectifs d'investissement définis par les clients. En outre, la période de temps et les préférences d'investissement ESG sont également prises en compte. UOBAM Robo-Invest vise à optimiser les portefeuilles avec une croissance stable à long terme en utilisant une stratégie hybride de fonds gérés activement et de fonds négociés en bourse (ETF). Le modèle d'optimisation maximise les rendements en fonction de l'objectif d'investissement et de la tolérance au risque des clients. La combinaison de l'IA et de la gestion de portefeuille a apporté des résultats impressionnants à UOBAM-Invest, le gestionnaire d'actifs ayant enregistré des rendements supérieurs à ceux de leurs indices de référence.
- 5a. Processus de négociationOutre les transactions effectuées en bourse, les transactions de gré à gré (OTC) ont également été remplacées par le commerce électronique. L'essor de la négociation électronique a généré un vaste ensemble de données à analyser tout au long du processus de négociation, de la pré-négociation à l'exécution.Figure 5 Exécution des opérations
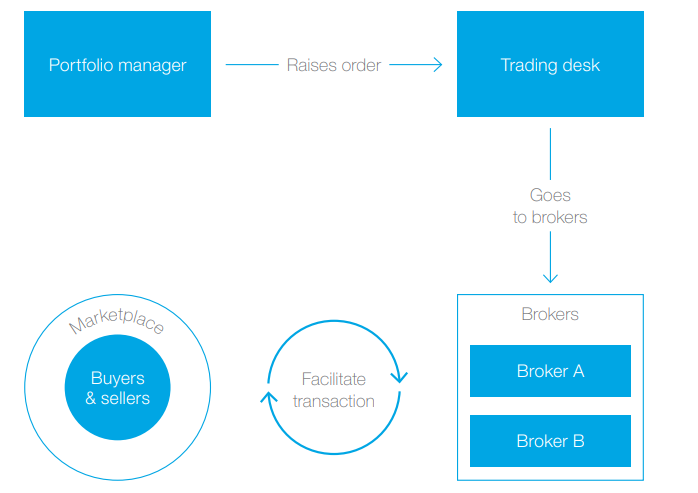
Au cours de la phase pré-négociation, les approches d'IA pourraient analyser les coûts de transaction avant l'exécution, y compris les écarts entre les cours acheteur et vendeur, le coût de l'impact sur le marché et les commissions. Les techniques d'IA pourraient saisir les relations non linéaires pour prédire l'impact sur le marché et fournir des informations supplémentaires par rapport aux modèles traditionnels d'impact sur le marché. Au stade de l'exécution de la transaction, l'algorithme pourrait minimiser le coût de la transaction en recommandant la taille et le moment appropriés de l'ordre. Par exemple, les modèles d'apprentissage automatique pourraient analyser l'inventaire des courtiers, les transactions historiques et les prix en apprenant activement à partir de ces données. Cependant, l'analyse post-négociation nécessite souvent une intervention humaine pour surveiller le risque et le résultat réalisé sur le marché. - 5b. Étude de cas : BlackRockBlackRock a tiré parti des techniques d'apprentissage automatique et d'IA pour analyser ses propres données de négociation afin d'identifier des schémas dans les coûts de transaction. Les traders de BlackRock pourraient utiliser les résultats générés par ces modèles pour obtenir une meilleure compréhension des transactions. En outre, l'application des techniques d'IA permet à BlackRock d'analyser d'énormes volumes de données textuelles et d'anticiper les changements probables dans les bénéfices futurs des entreprises. Par exemple, la technologie NLP pourrait transformer le texte non structuré en mesures exclusives du sentiment du marché ou des tendances commerciales. La technologie permet également d'analyser chaque jour plus de 5 000 transcriptions d'appels à bénéfices et plus de 6 000 rapports de courtiers, alors que l'approche traditionnelle prendrait beaucoup de temps car les rapports doivent être lus par un être humain.
Principales applications dans le domaine de l'assurance
- 6a. Automatiser et améliorer le processus de traitement des demandes d'indemnisationComme les données relatives aux sinistres existent sous différents formats, tels que des photos et des documents, il est difficile d'identifier et d'analyser ces données non structurées ou semi-structurées avec une grande efficacité. Par conséquent, l'un des principaux points problématiques du traitement des réclamations (par exemple, traitement tardif, insatisfaction des clients) est la mauvaise expérience du client et les longs délais d'attente. Par exemple, les assureurs peuvent mettre en place un système automatisé de première déclaration de sinistre (FNOL) grâce à l'IA. Ce système pourrait automatiser les aspects liés au contact avec les clients et à la gestion des sinistres, de sorte que le processus de déclaration pourrait être achevé sans intervention humaine. Au stade de l'évaluation du sinistre, l'estimation des dommages est confiée à un expert ou à un atelier de réparation automobile, ce qui peut prendre des jours ou des semaines. Grâce à la technologie NLP, l'assureur pourrait introduire un modèle d'apprentissage automatique qui classerait les sinistres sur la base des images des dommages subis par le véhicule et estimerait les frais de réparation à l'aide d'une vaste base de données. L'IA pourrait procéder à l'évaluation et autoriser le sinistre dans un délai très court, ce qui aiderait les assureurs à garantir la qualité et la rapidité du processus de règlement des sinistres. En outre, elle permet également aux assureurs de faire des observations à partir des audits de sinistres et de prévenir les fuites de sinistres.
- 6b. Étude de cas : Fukoku Mutual Life InsuranceFukoku Mutual est un assureur vie de premier plan, actif au Japon. Conformément à la tendance du secteur, Fukoku était aux prises avec des coûts opérationnels croissants en raison de l'inefficacité du traitement des demandes d'indemnisation. Elle a adopté des systèmes d'IA pour analyser et interpréter les données relatives aux demandes d'indemnisation, telles que les images des certificats médicaux, et pour calculer le montant des indemnités avec une grande précision. Afin d'éviter les erreurs de paiement, le système d'IA peut également vérifier s'il existe une quelconque violation des contrats d'assurance. L'utilisation de l'IA a permis de réduire considérablement le temps nécessaire au calcul de l'important volume de remboursements, tout en augmentant sensiblement la productivité.
- 7a. Optimisation des prixL'activité principale des compagnies d'assurance est de comprendre et d'anticiper le risque des clients et de prendre le risque à un prix approprié. Aujourd'hui, l'intégration de techniques d'apprentissage automatique dans la modélisation des risques a permis aux assureurs de mieux prédire différents événements. En conséquence, les assureurs ont pu affiner leurs modèles de tarification afin d'accroître leur rentabilité. Parmi les méthodologies couramment employées, citons le modèle linéaire général (GLM), LightBGM et les forêts aléatoires. L'équipe chargée de la tarification alimente le modèle avec les attributs historiques des polices, les informations sur les clients et les données relatives aux événements. Contrairement à l'approche traditionnelle qui construit des modèles de fréquence et de gravité pour prédire le nombre et le montant des sinistres, l'approche d'apprentissage automatique peut déduire directement le sinistre encouru. Elle fournit souvent un résultat plus précis car le modèle établit des relations non linéaires et peut utiliser une plus grande variété de variables.
- 7b. Étude de cas : AXA
Au Japon, 7-10% des clients d'AXA avaient un accident de voiture chaque année. Les pertes étaient considérables. Comme les techniques d'IA pouvaient s'appuyer sur davantage de données historiques pour fournir une analyse prédictive, l'équipe de science des données d'AXA Japon a décidé de créer un modèle d'apprentissage profond. Elle a utilisé TensorFlow, une plateforme d'apprentissage automatique open source développée par Google, pour développer le modèle expérimental à l'aide d'une forêt aléatoire et d'un réseau neuronal. De nombreux facteurs, tels que l'âge du conducteur et le type de véhicule, ont été identifiés et introduits dans le réseau neuronal à trois couches cachées. Finalement, l'approche d'apprentissage automatique a généré des prédictions avec une précision de 78%, permettant à AXA de fournir de meilleurs services de souscription avec une tarification plus précisePar ailleurs, AXA Tianping, l'un des plus grands assureurs de biens et d'accidents en Chine, a annoncé un partenariat avec une société de technologie de l'assurance, Akur8. Grâce à la technologie d'IA d'Akur8, AXA Tianping pourrait automatiser la modélisation des tarifs et améliorer le processus de tarification. Cela permettrait à AXA Tianping de développer plus rapidement un portefeuille de produits bien tarifés dans un environnement de risque dynamique.
Défis pour le développement de l'IA / ML dans le secteur des services financiers
- La qualité et la quantité des donnéesComme d'autres modèles empiriques, les modèles d'IA reposent sur la disponibilité et l'intégrité des données. Des données de mauvaise qualité peuvent facilement déclencher ce que l'on appelle le "garbage in, garbage out". La qualité et l'adéquation des données sont particulièrement importantes car les résultats de l'IA sont souvent pris pour argent comptant. Par conséquent, l'identification des problèmes liés aux données par l'évaluation des résultats du modèle peut ne pas être un exercice simple. En outre, les modèles d'IA nécessitent de grandes quantités de données pendant la phase d'apprentissage, souvent plus que ce qui est disponible.
- Le manque de confiance dans l'apprentissage automatique pour les décisions sensiblesLes modèles complexes d'apprentissage automatique ne sont pas faciles à interpréter et il peut être difficile, voire impossible, d'expliquer leurs prédictions. Faute de comprendre les modèles à boîte noire, tels que les réseaux neuronaux artificiels à plusieurs couches, les utilisateurs finaux peuvent avoir du mal à se fier à leurs résultats. C'est particulièrement vrai pour les régulateurs des services financiers et les banquiers qui travaillent sur des décisions à fort enjeu, car ils voudraient étayer leurs décisions par des explications complètes.
Ce que fait Accuracy
- Chez Accuracy, nous disposons d'une équipe de data scientists et d'un laboratoire technologique qui aident nos clients sur les tâches suivantes :Réalisation d'analyses stratégiques sur l'adoption de solutions IA / ML appropriées dans différentes fonctions de l'entreprise.
- Développer des modèles d'IA / ML qui répondent au mieux aux besoins de votre entreprise.
- Développement et mise en œuvre de plateformes et de systèmes alimentés par l'IA / ML.
- Concevoir des cadres de gouvernance des modèles d'IA / ML et mettre en œuvre les meilleures pratiques.
Chez Accuracy, nos experts du secteur des services financiers travaillent avec des banques et des institutions financières non bancaires sur des fusions et acquisitions, des transformations stratégiques, des modélisations quantitatives et l'adoption de solutions technologiques. Au cours des vingt dernières années, nous avons travaillé en étroite collaboration avec des institutions financières internationales et des petites et moyennes entités afin d'apporter de la valeur ajoutée à leurs activités.
Nicolas Darbo - Associé - Accuracy
David Chollet - Associé - Accuracy
Jean Barrere - Associé - Accuracy
Carl Chan - Directeur - Accuracy